
Membership Inference Attacks on Sequence Models
Published:
We study how to adapt membership inference attacks to sequence models such as language models and autoregressive image generators.
Our starting point is LiRA [Carlini et al., 2022], a strong shadow-model-based attack that compares how likely a sample score is under the in and out distributions estimated from shadow models. In the sequence setting, we write the attack as
\[\mathcal{A}(f; x) := \frac{\mathcal{N}(S(f; x) \mid \mu_{x,\mathrm{in}}, \Sigma_{x,\mathrm{in}})}{\mathcal{N}(S(f; x) \mid \mu_{x,\mathrm{out}}, \Sigma_{x,\mathrm{out}})}.\]LiRA is a strong practical baseline, but a naive transfer to sequence models misses important structure. Sequence models generate or score tokens conditionally,
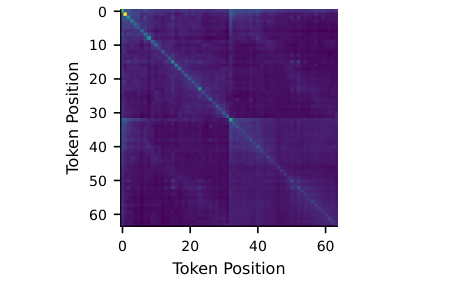
\[x_{t+1} \sim p(x_{t+1} \mid x_{1:t}),\]so per-token losses within a sequence are correlated. If we collapse a sequence to a single scalar, or keep token-level scores while treating them as independent, we discard signal that matters for privacy auditing.
We highlight two mismatched assumptions behind naive LiRA in this setting. First, it often assumes independence between multiple statistics from the same sample even though token losses within a sequence are correlated. Second, it allows the covariance to differ between members and non-members, even though in our experiments a shared covariance is often the better choice.

Mismatched Assumptions in Naive LiRA
A naive adaptation of LiRA to sequence models either averages per-token losses into one scalar or treats token-level losses as independent. We show that both simplifications are too crude for autoregressive models. Instead, we model the full vector of per-token losses and explicitly account for within-sequence correlations through a multivariate Gaussian model.
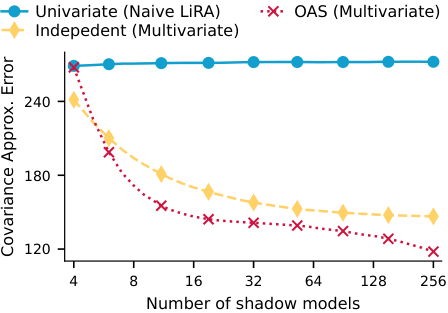
To make covariance estimation practical when the number of shadow models is limited, we study structured estimators. One of the key estimators we consider is OAS, which shrinks the maximum-likelihood covariance estimate toward a structured target:
\[\Sigma_{\mathrm{OAS}} = (1 - \alpha)\Sigma_{\mathrm{MLE}} + \alpha F.\]This gives a more stable covariance estimate in the small-sample regime.
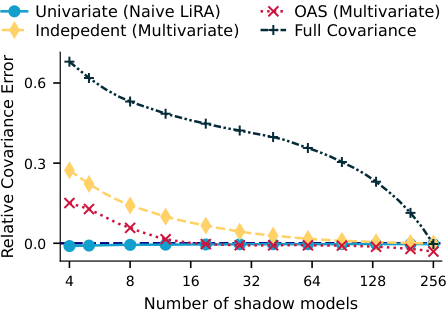
We compare three main variants. The Univariate attack is the naive baseline that reduces the sequence to one scalar. The Independent attack keeps token-level scores but estimates only a diagonal covariance. The OAS attack estimates a full covariance matrix through shrinkage. We also compare class-wise covariance estimation against a shared covariance between the in and out distributions, and find that the shared version is often preferable, especially when the number of shadow models is limited.
Experiments
We study three autoregressive settings: an LSTM trained from scratch, a fine-tuned Pythia 1b language model, and a Pixel-CNN++ image generator as a case study.
For the language experiments, we use the PersonaChat dataset and evaluate both average-case and worst-case canaries. In each language setting, we train 64 models so that every canary appears in exactly half of the training runs, and we evaluate attacks in a leave-one-out setup where each target model is audited with the remaining models as shadows. We also train a larger pool of 484 Pythia 1b models to study how performance scales with the number of shadows.
For the language settings, we focus on privacy auditing in the high-confidence regime and report TPR @ 0.01% FPR. The image case study is substantially harder, so there we highlight TPR @ 1% FPR instead.
Comparison of Different Attacks
Three results stand out.
First, sequence-aware variants consistently uncover much more memorization than naive LiRA. In the motivating example, adapting LiRA to explicitly account for sequence structure reveals up to 87.5x more memorization in the LSTM setting and 6.9x more in the Pythia setting.
Second, shared covariance estimation is often stronger than class-wise estimation. This appears both in covariance approximation error and in downstream attack performance.
Third, the best sequence-aware variant depends on the setting, but the univariate baseline is consistently weaker. On worst-case canaries, for example, the Independent Shared attack reaches TPR @ 0.01% FPR = 95.00% on LSTM and 99.30% on Pythia 1b.
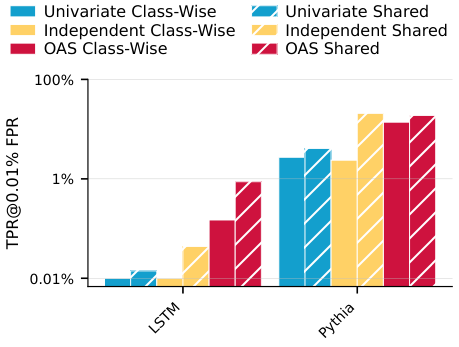
The image case study is much more challenging. In that setting, performance at 0.1% and 0.01% FPR is close to random guessing, and OAS is the only method that performs better than random guessing at 1% FPR.
The broader lesson is simple: sequence models need sequence-aware privacy audits. Otherwise, we risk underestimating memorization and overstating privacy.
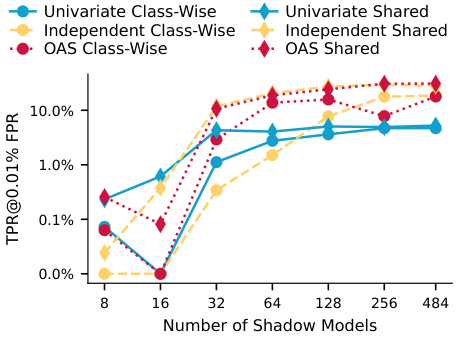
Impact of the Number of Shadow Models
We also study what happens as we increase the number of shadow models. More shadows improve attack calibration, but the gains are not uniform across methods. The univariate attacks plateau early, peaking around 32 shadow models in the Pythia scaling experiment, while more expressive estimators continue improving as additional shadows become available. For very small numbers of shadows, the Univariate Shared attack can be slightly better, but it becomes clearly worse once more shadows are available.
Why It Matters
Sequence models are trained on large corpora that may contain sensitive or copyrighted data. If our audits rely on the wrong statistical assumptions, they can miss memorization and make privacy risk look smaller than it really is.
Our main contribution is not a wholly new standalone attack. Instead, we show that a strong existing attack can be adapted to the statistical structure of sequence models with trivial overhead, and that this materially improves what we can detect.
Paper
Authors: Lorenzo Rossi, Michael Aerni, Jie Zhang, and Florian Tramèr.
The paper received the Best Paper Award at the DLSP Workshop at IEEE S&P 2025.
Read the paper on arXiv.
LiRA reference: Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramèr, “Membership Inference Attacks from First Principles,” IEEE Symposium on Security and Privacy (2022).